Named Entity Recognition — Clinical Data Extraction

In this Article we will briefly describe about:
1. What is Named Entity Recognition?
2. Why do we need NER and where is it applied?
3. What is Annotation and why do we need it?
4. NER Approach to build a model for NER — Clinical data extraction
- a. Data Extraction
- b. Data Preparation for spaCy
- c. Training NER Model
- d. Model Evaluation on new data
1. What is Named Entity Recognition?
Named Entity Recognition (NER) — also referred to as named entity extraction or identification — is an extraction technique that automatically identifies key information from text data and classifies them into predefined categories.
It is a subtask of information extraction that seeks to locate and classify named entities mentioned in unstructured text into pre-defined categories such as person names, organisations, locations, medical codes, time expressions, quantities, monetary values, percentages, etc.
2. Why do we need NER, and where is it applied?
It adds a wealth of semantic knowledge to your content and helps you to promptly understand the subject of any given text.
It is a form of Natural Language Processing that finds uses in analyzing unstructured text data such as emails, social media posts, product reviews, online surveys, research data, contractual documentation etc.
3. What is Annotation, and Why do we need it?
- Annotation is an added note that explains something in a text.
- Annotating usually involves highlighting or underlining key pieces of text and making notes in the margins of the text.
- By annotating a text, you will ensure that you understand key areas of focus, perspective of the text, etc.
- In-order for Training the NER Models we need annotated data.
- SpaCy does give you an option “prodigy” which can create labelled data

4. NER Approach for Clinical Data Extraction
Pharmaceutical companies save their lab notes and clinical trial data into databases to record their observations of certain drugs, molecules, and chemicals. NER can enrich drug research by extracting information from these unstructured data sources and use them in the testing of current and future drugs. Its applications can be taught to understand pharmaceutical jargon and search this data for topics, phrases and terms, for findings that are more relevant to the current research than initially discovered.
In the next steps we will focus on how we can build a NER model to identify the Disease within a text.
a. Data Extraction
The following GitHub repo has the annotated clinical text repo:(https://github.com/dmis-lab/biobert).
They have provided annotated 8 datasets on biomedical named entity recognition (https://drive.google.com/open?id=1OletxmPYNkz2ltOr9pyT0b0iBtUWxslh).
Once you download you will see a folder BC5CDR-disease. We will use this data for training and inference. In These tsv files each word is annotated using the BIO format. It uses BIO Format
here B-> Begin entity, I-> inside entity and O-> outside entity

So as you can see the Orange Boxes are Begin-Entity, Blue Boxes are Inside-Entity, and remaining are Outside-Entity
b. Data Preparation for spaCy
So given the files in BIO format data, we will be converting them into the format required for spaCy to train.
The format which it requires is as follows:
(sentence, {entities : [(start, end, label), (start, end, label)]})
So we have built a function which will help in doing the pre-processing and generates the required format and returns the sentence and labels for each record.
So when we call this function we will get the required data from File into Train_data , Test_data, Valid_data
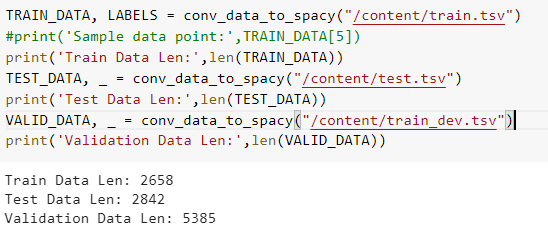
When we look at a single data point after the conversion, we see it as below, where the first part is the sentence, and next parts are entities against the text with start and end

c. Training NER Model
Here we have built a function which will train the NER model.
As per the below function :
- From line 6 to 12, we are loading the english code web medium size model to train the NER. If it is not present we are creating the pipe and adding.
- From line 15 to 16, we are adding the new labels which we created from above function.
- From line 19 to 22, we are disabling all other pipelines as we are only focusing on training a NER model.
- From line 26 to 33, we are using update function to update with the latest data and train the NER model, and it is done via multiple iterations. We also have shuffle as it helps in learning with some randomness.
And then we are training for about 20 iterations as shown below:
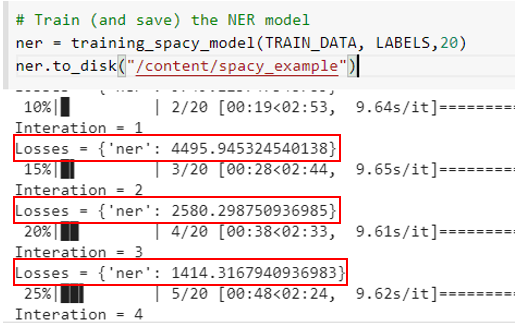
d. Model Evaluation on new data
So now that we have built a custom NER model, we would like to test how well the model performs.
For which we will load the saved ner model and do the inference as below.
So once we load, we will test it with a test data point, as shown below and we see that our NER model correctly identifies the disease:
TEST DATA POINT 1:

TEST DATA POINT 2:

Future enhancements and References
- For further improvements, we can collect more data and train much better models.
- Upon getting more data, we could use advanced deep learning techniques to enhance the model performance even better.
References:
- www.appliedaicourse.com
- https://www.youtube.com/watch?v=mmCmqOWHC5A&t=281s
- AI Engineering Youtube channel : https://www.youtube.com/watch?v=1ePkOSGoIFI
The full code for this post can be found on Github. I look forward to hearing any feedback or comment.
For few other case studies please refer below URL:
